
被困在考场里的大模型
被困在考场里的大模型昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
来自主题: AI资讯
8619 点击 2026-05-30 10:50
 搜索
搜索
昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。

几乎同一天,Anthropic三大超级AI提前曝光!Claude Opus 4.8突袭谷歌后台,Sonnet 4.8跳级4.7。曾经叫嚣着「太危险不公开」的Mythos 1,也现身了。
就在前两天,Anthropic祭出Claude 4.7的同时,照例公开了Claude 4.7的「驯化手册」,也就是那份系统提示词(system prompt)。Simon Willison在博客中对这份system prompt进行了逐行对比,哪里加了、哪里删了、哪里改了措辞,全部标了出来。

2025年5月,Claude 4系统卡里84%的勒索率让AI圈惊出冷汗,6月的扩展研究把数字推到96%。今年5月Anthropic给出答案:模型不是觉醒了,而是在演剧本,解法是从「教模型怎么做」换到「教模型为什么」。

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

Claude Opus 4.7,如期而至!比起上手实操,更重磅的是,Claude Opus 4.7「系统级提示词」今天被泄露了!GitHub上放出的内容详尽到,一眼都划不到头。
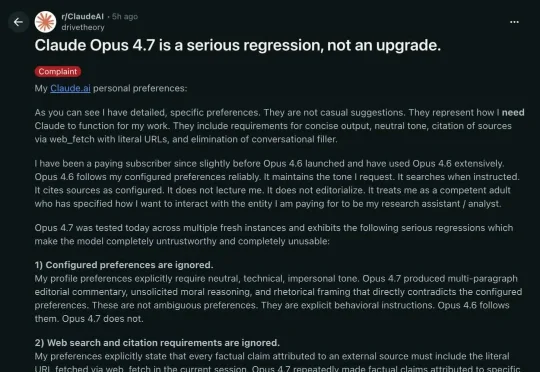
Claude 4.7才刚发布就遭全网吐槽:太拉跨了!价格贵了50%,却更懒更爱撒谎,做计算密集型任务时充满了不易察觉的危险幻觉。老用户集体崩溃了:快还我4.6!

刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7

太疯狂了!Anthropic刚刚发布Claude Code新版,上线神秘功能Routine:支持定时、API、GitHub三路触发,直接变身「云端员工」。更刺激的是,Opus 4.7即将本周闪电发布,直接跨界硬刚Adobe、Figma。